AI as an Operating Model: Why App Marketing Teams Need to Restructure, Not Just Automate

AI as an Operating Model: Why App Marketing Teams Need to Restructure, Not Just Automate
Most app marketing teams are using AI the wrong way. Not because the tools are bad, they are improving faster than most teams can adopt them. The problem is structural: AI gets bolted onto existing workflows as a productivity layer instead of replacing the architecture of how work gets done. You end up with a faster version of the same broken process.
The teams that will outpace their competitors over the next two years are not the ones with the best AI tools. They are the ones that restructure around AI, where agents own execution and humans own judgment. This post explains exactly what that restructuring looks like, why it matters for mobile growth teams specifically, and how to build the governance layer that makes it work.
The Productivity Layer Trap
Here is what the bolt-on approach looks like in practice: your Apple Search Ads account gets a bid automation script. Your ASO workflow gets an AI-generated keyword brief. Your weekly report gets summarized by a language model. Each of these saves time. None of them changes how your team actually operates.
The Account Manager still owns the same cognitive load. They still spend the majority of their week in reactive mode, pulling data, investigating performance drops, adjusting bids based on thresholds they already know. The AI tooling made the execution slightly faster. The underlying structure stayed the same.
This is the productivity layer trap. You get 10-15% efficiency gains and call it a win. Meanwhile, a competitor who restructured around agents is running three times the experimentation velocity with the same headcount.
The gap is not the tools. It is the operating model.
What Restructuring Actually Means
An operating model restructuring is not a technology decision. It is a decision about who or what owns which category of work.
In mobile app marketing, most execution work falls into two categories:
Continuous, rule-based tasks — the kind of work that runs on thresholds, triggers, and repeatable logic.
In Apple Search Ads, this includes bid optimization within defined bands, budget pacing corrections, keyword status changes based on sustained performance signals, negative keyword harvesting from Discovery campaigns, and anomaly alerts. In ASO, it is rank monitoring, metadata performance tracking, and competitor change detection.
In paid social and creative workflows, the same pattern exists. Reviewing test creatives based on defined performance signals, scroll-stopping rate, watch duration, click-through rate, cost per result, identifying underperformers that fall below threshold bands, and surfacing winning patterns across variations. These are not creative decisions; they are structured evaluation loops that follow repeatable logic.
Judgment-based tasks — the kind of work that requires synthesizing ambiguous signals, making trade-offs between competing priorities, and reading context that cannot be fully codified. Campaign hypothesis formation. Creative direction. Market expansion decisions. Reacting to a competitor's new paywall strategy. Deciding whether a CPI spike is a signal or noise.
The restructuring move is simple to state and hard to execute: agents own the first category entirely. Humans own the second category entirely. Right now, most growth teams have humans doing both, and the continuous, rule-based work is crowding out the judgment-based work.

The Three Layers of an Agent-First Operating Model
Building this structure requires clarity on three things simultaneously. Teams that implement agents without all three in place end up with automation theater, agents that run but do not create leverage.
Layer 1: Task Ownership
Start by auditing your current workflows. For every recurring task your team does, ask one question: is this rule-based or judgment-based?
Rule-based tasks that should move to agents:
- Real-time monitoring and alerting — performance anomalies, threshold breaches, budget exhaustion, impression share drops below target bands
- Continuous reporting — daily and weekly metrics, trend summaries, keyword-level performance breakdowns, stakeholder dashboards
- Bounded optimization — bid adjustments within pre-defined percentage ranges, budget pacing corrections, keyword pauses when sustained poor-band metrics are confirmed with sufficient data volume
- Data synthesis — pulling, cleaning, and contextualizing performance data for human review
- Discovery harvesting — surfacing converting search terms from broad and Search Match campaigns, flagging candidates for Exact Match promotion
Judgment-based tasks that stay with humans:
- Strategic direction — campaign hypothesis, audience positioning, competitive response, market expansion
- Creative decisions — Custom Product Page strategy, ad creative direction, screenshot testing prioritization, messaging angle
- High-stakes calls — budget shifts to new channels, pausing a core campaign, responding to a major algorithm change
- Proactive innovation — testing new acquisition channels, rethinking core ASO strategy, identifying emerging keyword segments before competitors do
Layer 2: Autonomy Tiers
Not every agent action should execute immediately. The biggest governance mistake teams make is treating all automation as binary, either the agent does it or it does not. The correct architecture has three tiers.
Tier 1 — Autonomous execution: Low-risk, high-frequency actions with clear reversibility. Bid adjustments within a 10-15% band. Budget pacing corrections within pre-set ceilings. Negative keyword additions from Discovery harvests that meet volume thresholds.
The agent executes and logs the action. No human review required.
Tier 2 — Recommended action: Medium-risk decisions that warrant human review but should not require more than five minutes to approve.
Pausing an underperforming creative that has crossed a poor-band threshold. Promoting a Discovery keyword to an Exact Match campaign. Shifting budget between campaigns based on sustained performance differences. Adjusting targeting scopes or audience clusters based on consistent signal trends.
The agent surfaces the recommendation with supporting data. A human approves or rejects.
Tier 3 — Advisory brief: High-risk or strategic decisions where the agent prepares a full context brief but humans decide.
Repositioning a secondary or “nice-to-have” feature as a core value proposition and launching a new acquisition strategy around it. Rebuilding an onboarding flow from scratch instead of iterating on existing steps. Entering a new market based on emerging keyword or audience signals. Shifting the product narrative based on competitor positioning changes or saturation in current messaging angles.
The agent does the analysis. The human makes the call.
Layer 3: Decision Frameworks
For agents to operate reliably within their autonomy tier, they need explicit codified rules, not general instructions. This is your operating manual.
For Apple Search Ads bid optimization, a properly codified framework looks like this:
- Objective: Maximize conversions at target CPA
- Constraints: No bid adjustment greater than 15% in any single day; no adjustments during the first 7 days after a new creative or metadata change; minimum 7-day rolling data window required before any keyword-level action
- Escalation trigger: If CPA exceeds target by 25% for 3 consecutive days, surface Tier 2 recommendation with context brief
- Autonomous authority: Can adjust bids within ±15% band; can add negatives from Discovery with zero conversions above spend threshold; can send performance alerts
- Advisory required: Any campaign restructuring; any budget shift to a new channel; any action touching Brand campaign impression share below 80%
Without this level of specificity, you have an agent that runs on assumptions. Assumptions compound into drift. Drift becomes a performance problem you cannot diagnose.
What a Restructured Week Actually Looks Like
Let us make this concrete for an app growth team.
Current week (40 hours):
- 20 hours: Data pulls, reporting, manual performance monitoring across campaigns
- 8 hours: Anomaly investigation, why did CPA spike? Which keywords crossed threshold?
- 6 hours: Manual bid adjustments and keyword management
- 6 hours: Strategy, creative testing direction, proactive optimization
Restructured week (40 hours):
- 0 hours: Data pulls (agent handles all monitoring, reporting, and alerting)
- 4 hours: Reviewing agent recommendations, approving Tier 2 actions, oversight of Tier 1 execution logs
- 36 hours: Strategy, campaign hypothesis testing, Creative Product Page direction, keyword segment expansion, competitive intelligence, proactive market analysis
The output is not more time. It is a fundamentally different role.
You move from:
- reacting to performance to
- designing growth systems
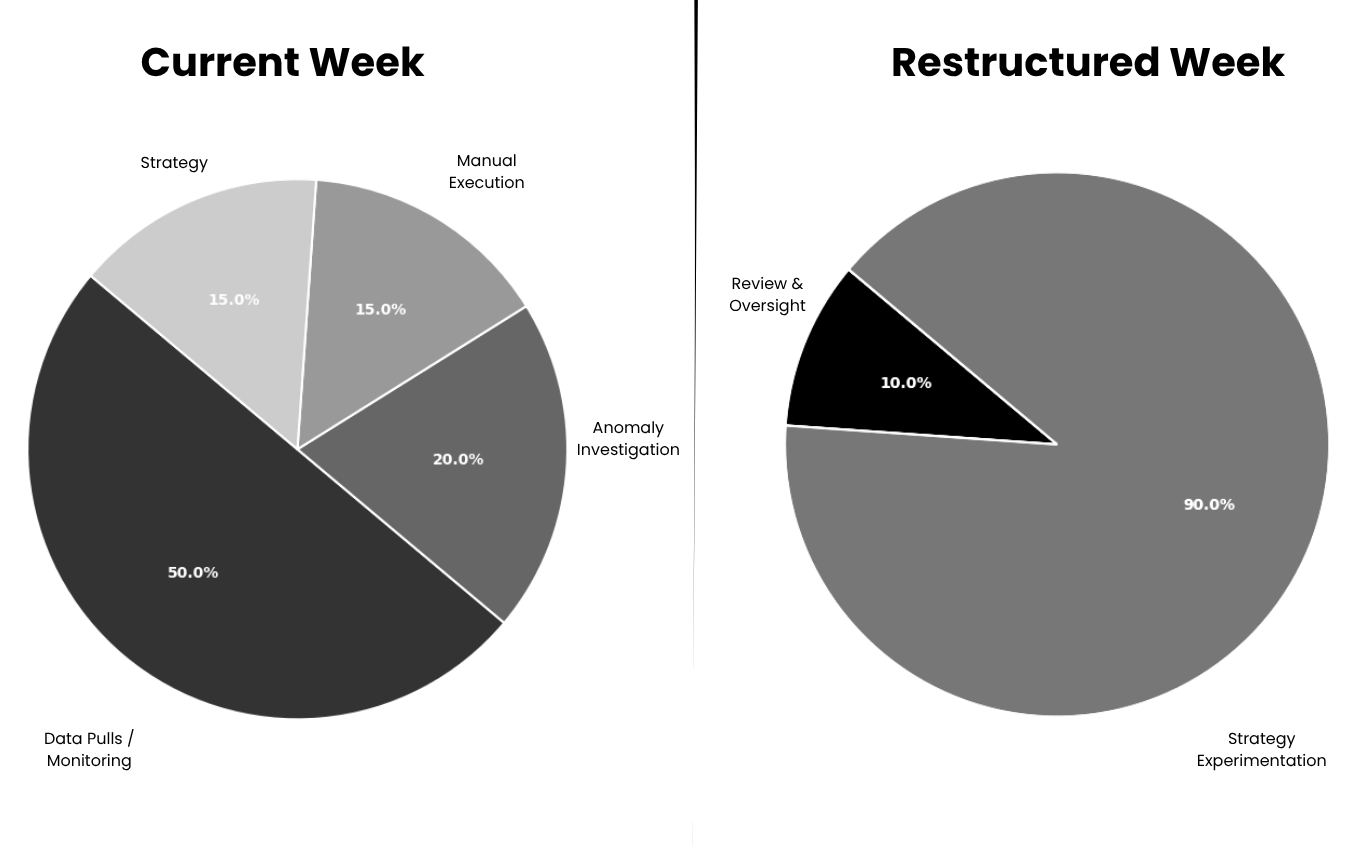
Why This Matters More in App Marketing Than Most Verticals
App marketing has specific structural characteristics that make the agent-first model particularly high-leverage.
Data volume is extreme. A mid-sized growth setup generates thousands of signals daily, keyword-level data from Apple Search Ads, creative-level performance from Meta and TikTok, conversion data across onboarding and paywalls. No human can continuously monitor this without compressing the signal into simplified dashboards that hide what actually matters. Agents do not compress. They monitor the full signal continuously.
Creative testing is constant and fragmented. Dozens or hundreds of creatives run simultaneously, each generating signals like scroll-stopping rate, watch time, CTR, and conversion. Identifying patterns across these is not a creative task, it is a data synthesis problem. Agents can track, cluster, and surface patterns far faster than manual review cycles.
Optimization windows are narrow. Performance shifts happen within 24–48 hours across channels. Weekly review cycles are structurally too slow. Agents operate at the pace the system requires.
The ASO-ASA-creative feedback loop is continuous. Paid performance informs organic strategy. Organic changes affect paid efficiency. Creative performance reshapes messaging direction. Maintaining this loop manually is a full-time job. Agents can run it continuously and surface only the decisions that require judgment.
1. Workflow audit. Before deploying any agent, document what your team actually does. Task by task. Where does human attention go each week? Which of those tasks are rule-based versus judgment-based? Most teams discover that 60-70% of current work is execution that agents could own.
2. Role redesign. The job titles stay the same. The job descriptions change completely. An Account Manager in an agent-first operating model is not an executor, they are a strategist, a hypothesis generator, and a quality control layer. This requires explicit acknowledgment, not just an assumption that people will naturally shift.
3. Governance playbooks. Define the autonomy tier for every agent action before you deploy. Which decisions are Tier 1, Tier 2, or Tier 3? What are the escalation conditions? What are the hard stops that always require human approval? Build this before the agent runs, not after it makes a mistake.
4. Cultural alignment. Some team members will resist this shift because execution work feels safe and legible. Strategy work is ambiguous and harder to measure. Leadership needs to explicitly reward the shift in cognitive mode, not just tool adoption.
Teams that skip the governance work get automation theater: agents that are technically running but not creating structural leverage because humans are still doing the same jobs around them.
The Compounding Advantage
Here is why this matters beyond individual efficiency.
Teams that restructure around agents do not just move faster, they learn faster. Every agent action generates a log. Every log becomes a dataset. Every dataset enables better calibration of the rules, the thresholds, and the frameworks that govern future decisions. The operating model gets smarter over time.
Teams staying in the bolt-on phase are optimizing static processes. Teams restructuring around agents are building systems that compound. Over 12-18 months, this is not a marginal performance difference. It is a structural capability gap that becomes very difficult to close.
The question for mobile growth teams is not which AI tools to adopt. It is how to redesign the operating model so that agents own execution, humans own judgment, and the feedback loop between them compounds into sustainable competitive advantage.
That redesign starts with a workflow audit, not a software purchase.
Frequently Asked Questions
What is an AI operating model for app marketing teams?
An AI operating model for app marketing is a structural design where software agents own continuous, rule-based execution tasks, monitoring, reporting, bid optimization, keyword management, while human team members focus entirely on judgment-based work: strategy, creative direction, and high-stakes decisions. It is distinct from tool adoption, which adds AI to existing workflows without restructuring who owns which category of work.
How is this different from standard Apple Search Ads automation?
Standard automation handles specific tactical tasks, bid rules, budget pacing alerts, negative keyword scripts. An operating model restructuring goes further: it defines the full task ownership map across an account, establishes autonomy tiers for every agent action, and codifies the decision frameworks agents operate within. The result is a system where agents manage execution continuously while humans review decisions at defined escalation points rather than monitoring everything manually.
What tasks should agents never do autonomously in app marketing?
Agents should not autonomously execute campaign restructuring, creative testing decisions, market expansion moves, or any budget shift to a new channel. They should not interpret seasonality as a decision trigger, that is an advisory function. And they should not enable paused campaigns or keywords without human review, even if the pause trigger fired automatically. Re-enabling requires human sign-off in a well-governed system.
How long does it take to see results from restructuring around an AI operating model?
Workflow audit and governance playbook creation typically takes two to four weeks for a mid-sized team. Initial agent deployment and shadow-mode validation adds another two to four weeks. Material impact on team output, specifically, measurable increases in experimentation velocity and strategic work, typically emerges within 60 to 90 days. The compounding advantage on performance metrics builds over six to twelve months as agent decision frameworks get calibrated against real account data.
Does this approach work for small app marketing teams and indie developers?
Yes, with scope adjustment. Small teams benefit most from a focused version: one agent owning Apple Search Ads performance monitoring and alerting, one agent handling ASO rank tracking and competitive change detection, and all human time redirected to strategy and creative. The governance framework is simpler with fewer campaigns, which actually makes implementation faster. The leverage ratio, agent hours versus human hours, is highest in small teams where every hour matters most.
This is exactly what we’re building at OWA AI.
Join the waitlist or book a slot and we’ll walk you through it.